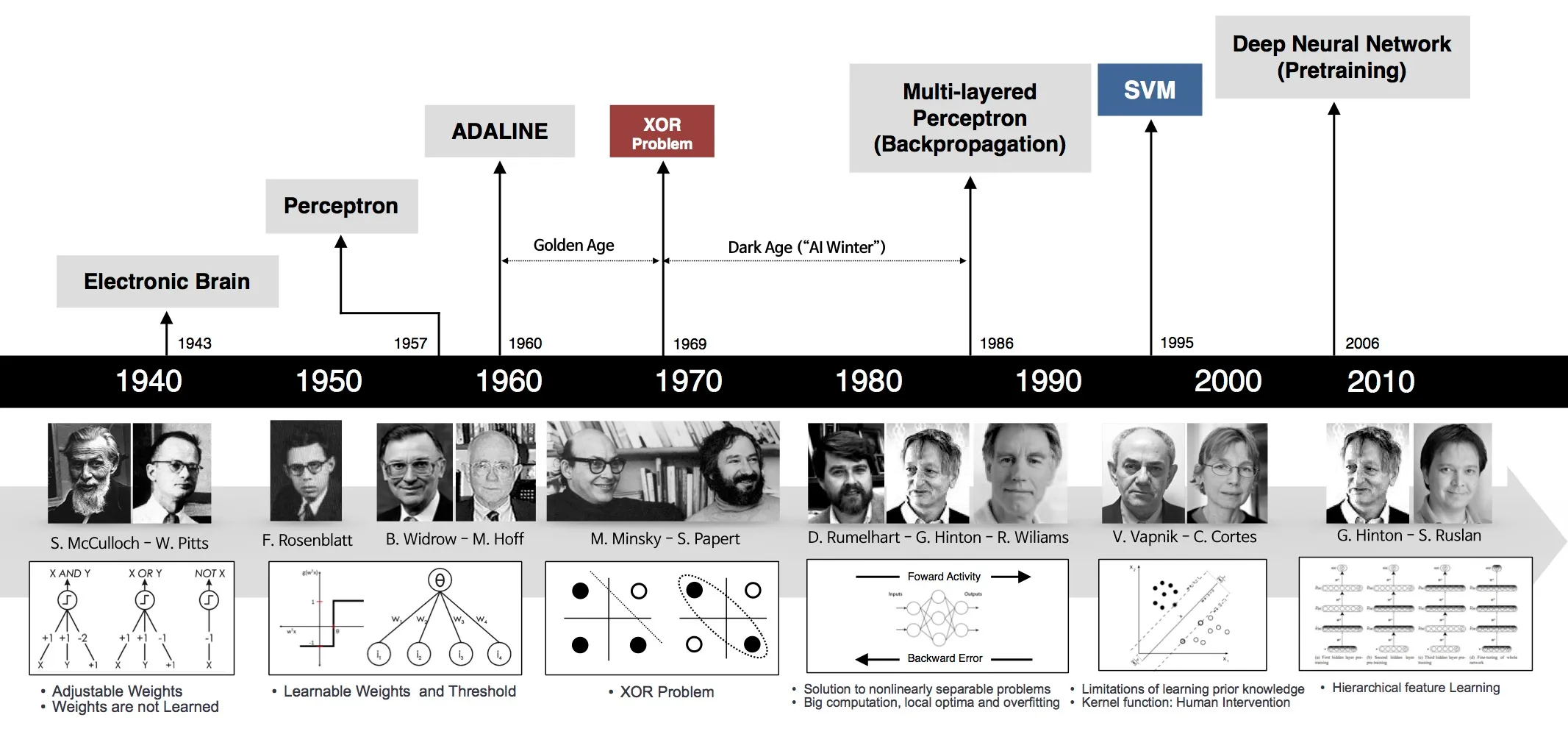
Early neural networks, like the original perceptron (single layer) from the 1950s and the later multilayer perceptron from the 1980s, worked by adding up inputs multiplied by simple numbers (weights) and then passing the total through a basic function that decided whether the “neuron” fired. At first these functions were just on/off thresholds but later they used smooth curves called "sigmoids" which are still relevant.
Sigmoid functions were heavily used in early neural networks, but they are largely replaced in modern deep learning by functions like ReLU (Rectified Linear Unit) because sigmoids suffer from vanishing gradients. But sigmoid functions are still used in specific cases.
The earliest systems, like the original perceptron hardware, ran on custom analog or early digital hardware, not necessarily mainframes or PCs.
The not so early systems ran on big mainframes and the first personal PCs and were programmed in languages like FORTRAN and later C.
In early systems, the code often had to manually implement the learning algorithm, including backpropagation for multilayer networks.
We still use backpropagation, and others but the ways we implement have changed. By "manually" I mean "no external libraries to assists".
So, “manually” refers to the labor-intensive, low-level coding to make learning happen compared to today, where AI devs can use ready-to-use tools to quickly make those happen.